Wearable Two-Factor Authentication using Speech Signals Resilient to Near-Far Attacks
Reducing the level of user effort involved in traditional two-factor authentication (TFA) constitutes an important research topic. An interesting representative approach, Sound-Proof, leverages ambient sounds to detect the proximity between the second factor device (phone) and the login terminal (browser). Specifically, during the login session, the browser and the phone each record a short audio clip, and the login is deemed successful only if the two recorded audio samples are highly correlated with each other (and the correct password is supplied). Except of entering the password, Sound-Proof does not require any user action (e.g., transferring PIN codes or even looking-up the phone) – mere proximity of the phone with the terminal is sufficient to login. This approach is highly usable, but is completely vulnerable against far-near attackers (as shown in our recent work from CCS’16), i.e., ones who are remotely located and can guess the victim’s audio environment or make the phone create predictable sounds (e.g., ringers), and those who are in physical proximity of the user.
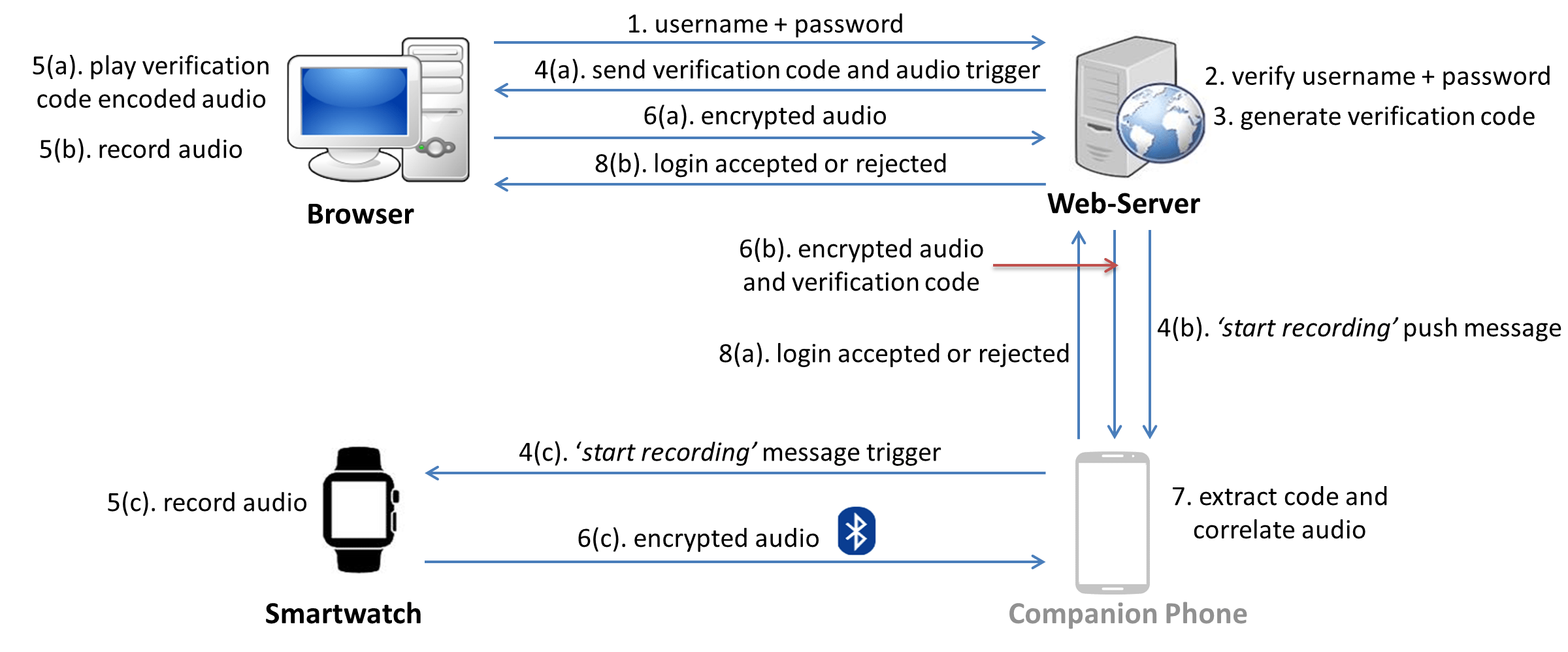
Figure 1: Architecture of Listening-Watch, a wearable TFA scheme. Figure shows an implementation of Listening-Watch using a smartwatch. A specialized bracelet with low sensitivity microphone can be used instead of the smartwatch. The phone is not serving the role of the second factor, it is only used as a companion device.
In this paper, we propose a complete re-design of the sound-based TFA systems to thwart both remote and proximity attacks, while still retaining their minimal-effort property. Specifically, we propose Listening-Watch, a TFA mechanism based on a wearable device (watch/bracelet) and browser-generated random speech sounds (not ambient sounds). Figure 1 depicts the architecture and concrete steps followed in Listening-Watch. In this scheme, as the user attempts to login, the browser plays back a short random code encoded into human speech, and the login succeeds if the watch’s audio recording contains this code (decoded via speech recognition technology) and is similar enough to the browser’s audio recording (i.e., audio recorded through the microphone at the login terminal). Listening-Watch offers two key security features: (1) use of random code encoded into audio to withstand remote attackers, and (2) use of low-sensitivity microphone (that cannot capture distant sounds) found in current wearable devices to defeat proximity attackers. It is important for any authentication system to defeat proximity attacks in order to provide physical security.
A remote attacker against Listening-Watch, who has guessed the user’s environment, will be defeated since authentication success relies upon the presence of the random code in watch’s recordings. Furthermore, a proximity attacker against Listening-Watch will be defeated unless it is extremely close to the watch/bracelet. This is because, unlike smartphones, the microphones available on current smartwatches (or specialized bracelets) are not high quality recorders, probably due to their constrained form factor and low-cost. However, they are designed to work well to receive voice/speech commands from the user when placed close to the speech source. Due to this quality of a wearable microphone, it can only capture sounds from a close vicinity.
Unlike traditional TFA, Listening-Watch does not require the users to perform any actions while attempting to login to the system except entering their credentials. Interaction may be needed only in occasional cases where terminal cannot play back audio and require a fall back authentication process. Although there is the presence of active sounds in the authentication process, Listening-Watch does not require the user to interact with the second authentication factor. So Listening-Watch is effectively a minimal-interaction approach that significantly reduces the interaction between the user and the authenticating token.
People
Faculty
Student
- Prakash Shrestha (PhD student)
Publication
- Press @$@$ to Login: Strong Wearable Second Factor Authentication via Short Memorywise Effortless Typing Gestures
Prakash Shrestha, Nitesh Saxena, Diksha Shukla and Vir Phoha
In the IEEE European Symposium on Security and Privacy (EuroS&P), Sep 2021. - Listening Watch: Wearable Two-Factor Authentication using Speech Signals Resilient to Near-Far Attacks .
Prakash Shrestha and Nitesh Saxena
To appear in ACM Conference on Security and Privacy in Wireless and Mobile Networks (WiSec), June 2018.
[pdf]